Bienvenue sur le tout premier article du blog !
Et pour son lancement, nous faisons le même parallèle qu’avec le début de tout projet Qlik réussi : nous commençons par poser les bases. Notre ambition est de partager avec vous notre vision et de consolider notre expérience au sein de contenus accessibles, rigoureux et utiles.
Sur ce blog, nous traiterons de sujets à la fois très techniques (scripting, modélisation, performance) et plus larges (la BI moderne et l’écosystème Qlik).
Pourquoi Qlik ? Les Fondamentaux
Souvent, les données de votre activité (finances, RH, commandes, etc.) sont enregistrées dans une ou plusieurs bases de données, gérées par des logiciels spécifiques. Si ces outils sont excellents pour l’opérationnel, ils ne proposent que rarement des fonctionnalités d’analyse et de statistiques avancées.
L’un des usages clés de Qlik est de rendre cette donnée disponible au-delà des utilisateurs du logiciel de gestion, en fournissant des capacités d’analyse supérieures.
Pour y parvenir, les grandes phases d’un projet sont toujours les mêmes :
- Se connecter à la source et extraire la donnée.
- La transformer en un modèle de données optimisé.
- Créer des indicateurs et un design pertinent.
Comme vous l’avez compris, la première étape est de maîtriser la source. Nous allons nous concentrer sur les phases critiques souvent négligées :
- Comprendre la structure de la source de données.
- Explorer son contenu réel pour préparer la modélisation.
Ces étapes sont indispensables pour tous les modèles décisionnels performants, découvrez comment les maîtriser.
Phase 1 – Comprendre la structure et la logique de la base de données
La plupart des projets Qlik s’appuient sur une ou plusieurs bases de données issues de logiciels métiers : gestion financière, RH, production ou logistique. Ces systèmes stockent la donnée dans un modèle relationnel, optimisé pour l’opérationnel mais rarement pensé pour l’analyse.
Pour le développeur, cette première phase est un travail de « mineur » : la documentation est souvent incomplète et les relations entre les tables sont loin d’être explicites. Elle est souvent fastidieuse et très technique.
Pour éviter d’avancer à l’aveugle, une cartographie de la base est indispensable. Nous allons vous partager des outils et astuces pour accélérer et industrialiser cette étape cruciale d’identification des éléments suivants :
- Les schémas et tables pertinentes.
- Les relations implicites et les clés fonctionnelles.
- Les champs porteurs de la valeur métier.
Maîtriser cette cartographie est la clé pour simplifier la suite du projet et la préparation de votre modèle de données Qlik.
Accéder au schéma
La première action consiste à récupérer le schéma complet de la base de données afin d’obtenir une vue détaillée de sa structure. Prenons l’exemple d’une base PostgrSQL, même s’il est possible de faire l’équivalent pour d’autres technologies.
Un script simple permet de lister automatiquement l’ensemble des tables et colonnes. Il suffit de se connecter en renseignant la chaîne de connexion, puis d’exécuter le script suivant :
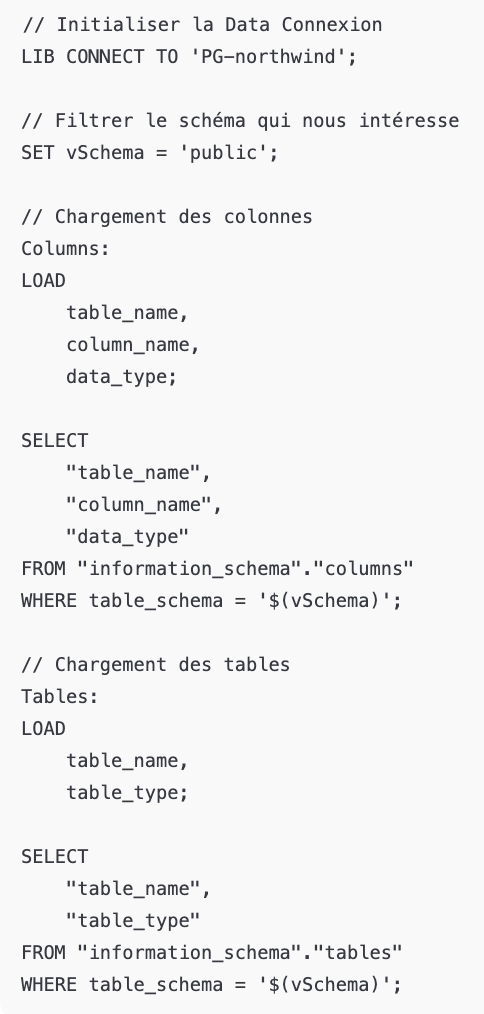
Grâce à cette extraction, on peut rapidement créer un tableau de bord d’exploration structurelle décrivant :
- La liste des tables
- Les types de champs
- La présence de clés
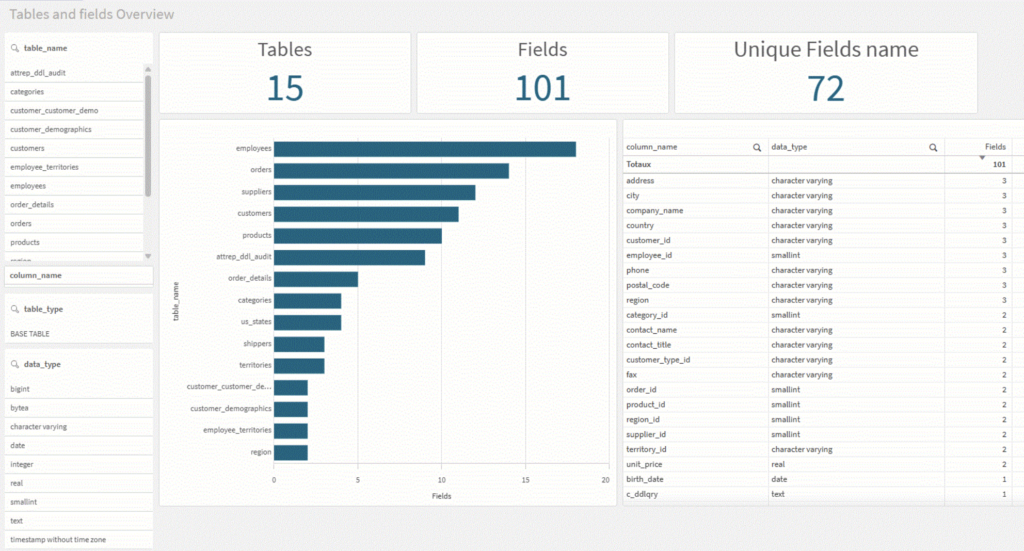
Pourquoi cette cartographie est indispensable ?
Cette première analyse permet :
- D’évaluer la qualité du modèle relationnel
- D’anticiper les transformations à prévoir pour un modèle décisionnel
- De repérer les champs techniques inutiles
- De comprendre la granularité des données
- De détecter les tables de faits, de dimensions, ou les tables mixtes,
- Identifier les clés et les relations entre tables,
Il s’agit d’une étape où l’on commence à imaginer la structure finale du modèle Qlik, en gardant en tête que le modèle d’origine ne va jamais être utilisé tel quel.
Des transformations, fusions et enrichissements seront systématiquement nécessaires.
Phase 2 – Explorer le contenu réel pour préparer la modélisation
Une fois la structure de la base de données cartographiée, l’étape suivante consiste à extraire les données pour les rendre consultables dans Qlik. Cette phase doit être optimisée pour être rapide, car elle sera répétée jusqu’à ce que nous ayons identifié toutes les données pertinentes.
Stratégie d’extraction selon la volumétrie
La manière dont nous extrayons les données dépend fortement de la volumétrie des tables sources :
- Volumétrie Raisonnable : Nous procédons à un chargement complet de toutes les lignes de données.
- Volumétrie Importante : Pour les tables massives, nous privilégions le chargement partiel.
Le script d’extraction et le rôle du QVD
Notre approche est de réaliser un “SELECT *” sur toutes les tables pertinentes du modèle de données et de les stocker immédiatement dans des fichiers QVD.
Ce chargement initial se fait grâce à un script assez simple, que voici :

Cette méthode présente deux avantages majeurs :
- Vitesse : Le QVD est un format optimisé pour Qlik, rendant les rechargements futurs quasi instantanés.
- Séparation : Les QVD servent de couche de stockage brute, isolée de la logique de transformation.
Préparation pour la consultation : l’astuce “Qualify”
L’astuce “Qualify” permet de préfixer tous les champs par le nom de leur table source. L’objectif est simple : éviter la création automatique de liens entre les tables dans le modèle de données de Qlik. Pour cette phase d’exploration, nous voulons juste consulter les tables de manière isolée, sans structure décisionnelle.

L’exploration à l’aide de la recherche intelligente
Une fois les données chargées, l’application Qlik (dans une feuille dédiée à l’exploration) devient un outil de recherche puissant. Si vous cherchez une valeur spécifique sans savoir dans quel champ elle est stockée, la recherche intelligente de Qlik est votre meilleur allié. Elle vous permet de trouver des données et de remonter à leur source, même au sein d’un modèle que vous ne maîtrisez pas encore.
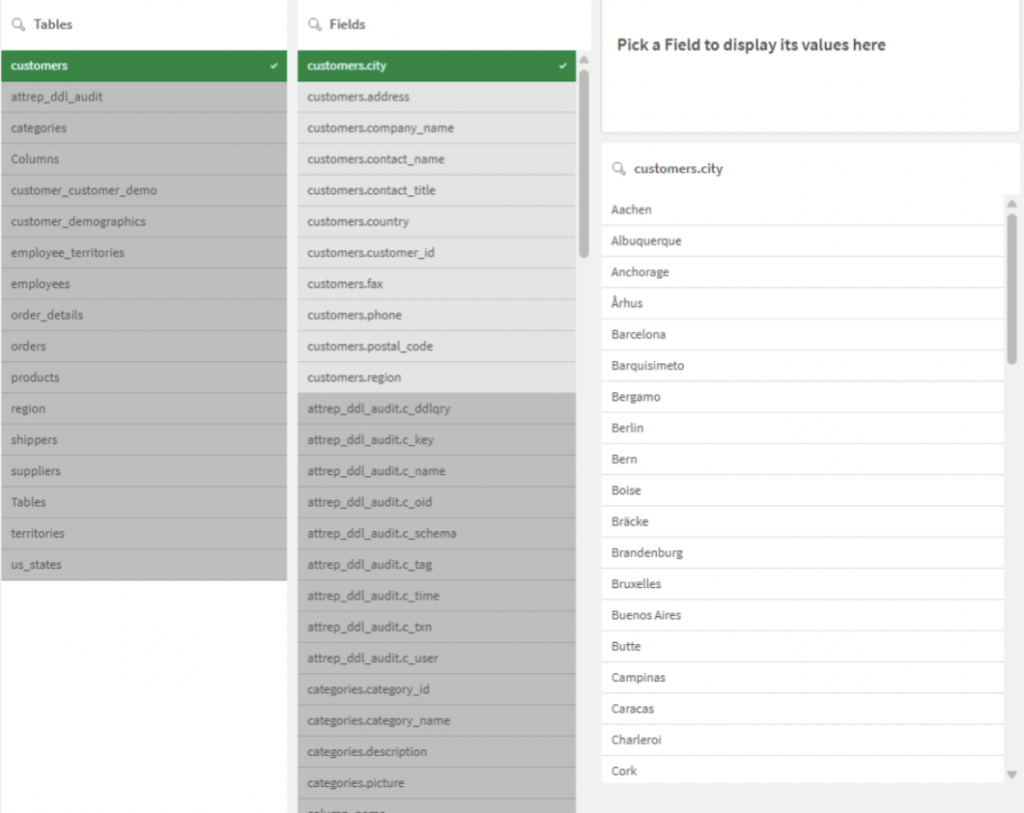
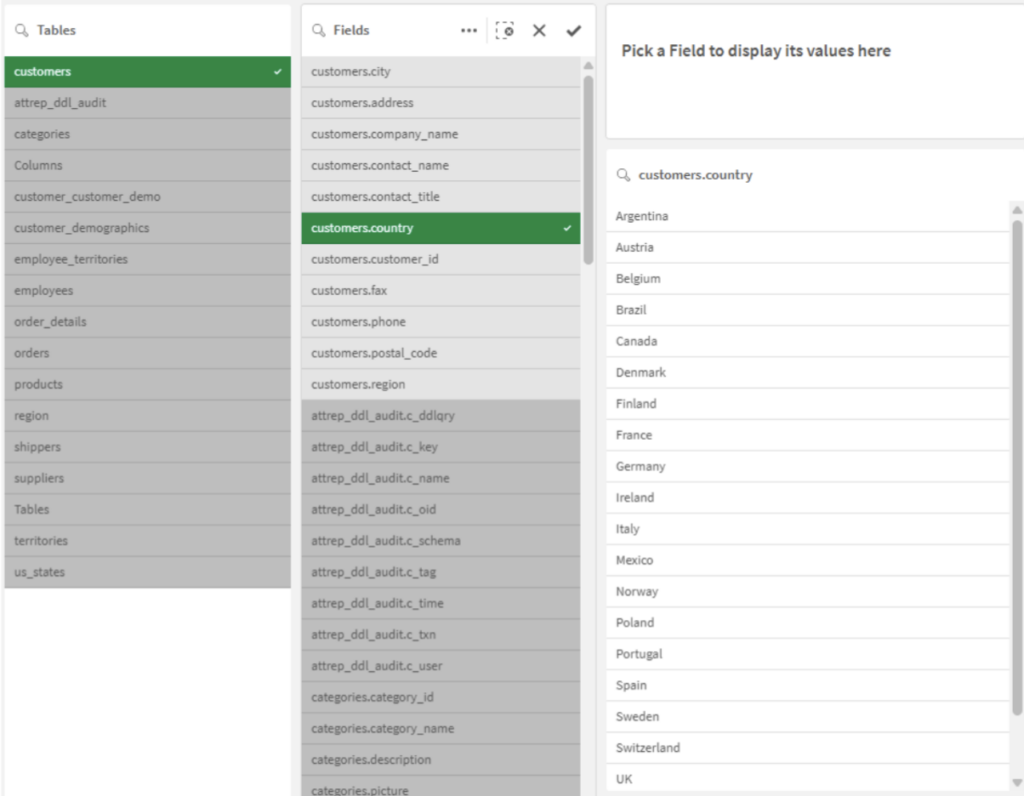
Optimisation pour l’exploration
Pour garantir la rapidité de cette phase, il ne faut pas oublier d’intégrer cette variable dans votre script :
“SET CreateSearchindexOnReload=0”
Cela évite à Qlik d’indexer le contenu de tous les champs lors du chargement, accélérant ainsi le temps de rechargement pendant que vous travaillez sur l’extraction. (Notez également que le chemin de stockage des QVD sera géré par des variables de projet à adapter selon votre système de fichiers.)
Cette méthode d’exploration s’applique à tout projet Qlik s’appuyant sur une base de données. Sa rapidité de mise en œuvre en fait un outil d’aide à la décision technique et fonctionnelle.
En effet, cet environnement d’exploration est idéal pour le dialogue avec les experts métiers (développeurs, utilisateurs, administrateurs de la base de données) afin de valider la pertinence des données et d’établir les règles de gestion nécessaires aux indicateurs.
Voici l‘application d’exemple à utiliser : Heydata_1 – GoaGS – 1.qvf
Une fois la donnée source maîtrisée et son usage futur défini, nous pouvons basculer vers les étapes d’industrialisation de l’extraction, qui sera l’objet de notre prochain article.
À bientôt
Leave a Reply